Bilibili动态网页的爬取(一)评论篇
预备知识:
- python语言基础
- python requests库, Bs4库, json库, 以及正则表达式(regex)的使用
- HTML/CSS和Jquery的基本知识
动态网页简介
不同于一般的静态网页(我们可以通过直接爬取HTML代码获取想要的信息),Bilibili采取的是通过发送Jquery请求,然后由JS动态生成网页。而事实上,现在越来越多的网页都采用这种方式获取信息,好处是显而易见的,页面的信息可以由服务端自动生成,大大减少了维护量,同时由于网页的信息难以直接获取,也有效组织了爬虫和黑客的攻击(加大了我们操作的难度)。
为什么是Bilibili
因为Bilibili基本没有设置反爬,方便我们锻炼爬取动态网页的能力 因为我喜欢Bilibili啊( ̄▽ ̄)”
正式开始(评论)
首先我们要知道这么一个基本事实:B站在请求弹幕信息时使用的oid=cid(我也不知道是什么),在请求评论信息时使用的oid=aid(也就是av号),大概这也是B站为什么要把av号全部换成bv号吧(然并卵)。
接着就可以开始操作了。首先打开av170001,按照惯例F12(右击,检查元素),选择Network选项卡,选择下方的JS,像这样:
紧接着我们自由切换底下的页数
发现检查页发生了变化,点这个(到处点):
发现下面有了这个:
拖到底下,看这个: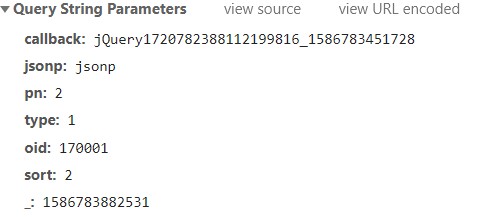
这里列出了几项数据,重要的只有这几项:
type(照抄,不知道是什么)
pn(评论的第几页)
oid(aid)
sort(照抄,不知道是什么)
来到顶部,看到这一串东西:

我们可以无视后面的jQuery请求,只提取重要的部分(后面的都是请求时自动生成的):
格式是:api.bilibili/x/v2/reply?pn=xxx&type=xxx&oid=xxx&sort=xxx
我们只需要把上面得到的数据填进去就可以了。
我们访问这个页面,不出所料,返回的是一个json格式的页面。(然后你就懂了)
问题来了,如果给的是bv号,如何得到av号?方法一:百度得到av和bv转换的算法。方法二(更优):考虑到为以后获取弹幕做准备,我们还需要得到cid(至少我没找到算cid的方法),可以直接请求bilibili.com/video/av170001得到网页,一番瞎眼查看后发现,只需要用正则表达式匹配出\"cid=\d+&aid=\d+&attribute=\d+&bvid=\w+&这样一个字符串即可(然后你就又懂了)
附上部分代码:
提取id:
1 | class VideoId: |
解析评论json:
1 | def parseCM(jsonText, comments): |
喜欢我的不妨继续关注哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦哦!ヾ(≧▽≦*)o

